

Зачастую наши пользователи парсят сайты не целиком, а забирают только определенные страницы, или делают поиск на сайте доноре по определенному набору критериев. Запуск за запуском этот набор критериев может меняться, и чтобы этот подход работал вам нужно было менять этот набор напрямую в конфигурации диггера. Для некоторых это не очень удобно, поскольку без определенного понимания формата YAML, при редактировании конфигурации можно сделать ошибку и сломать парсер. Так как Diggernaut может работать с XLSX и CSV файлами как с HTML страницами, если они доступны для скачивания в сети, то это могло бы быть решением. Однако, далеко не у всех есть сервер или просто сайт, на который они могли бы загрузить Excel файл. Также, согласитесь, что это не очень удобно загружать файл на сервер каждый раз, когда вы сделали в нем изменения.
Гораздо проще и быстрее для этого использовать Google Spreadsheets. И сейчас мы расскажем вам, как это сделать правильно.
Для начала вам нужно иметь аккаунт в Google. Если у вас его еще по какой то причине нет, зарегистрируйтесь в Google. Это даст вам доступ к сервису Google Docs.
Далее зайдите в Google Spreadsheets и создайте новую таблицу.

Зададим таблице имя и внесем в нее данные. Мы можем вносить в таблицу комплексные данные, используя много столбцов, и ваш парсер сможет с ними работать. Однако в данном случае мы будем использовать только один столбец и внесем туда список ASIN товаров в магазине Amazon. На самом деле мы могли бы внести туда просто список URL, которые нужно собрать, но ваш парсер должен корректно работать с данными в таблице, или, другими словами, иметь подходящую логику для заданного набора данных.
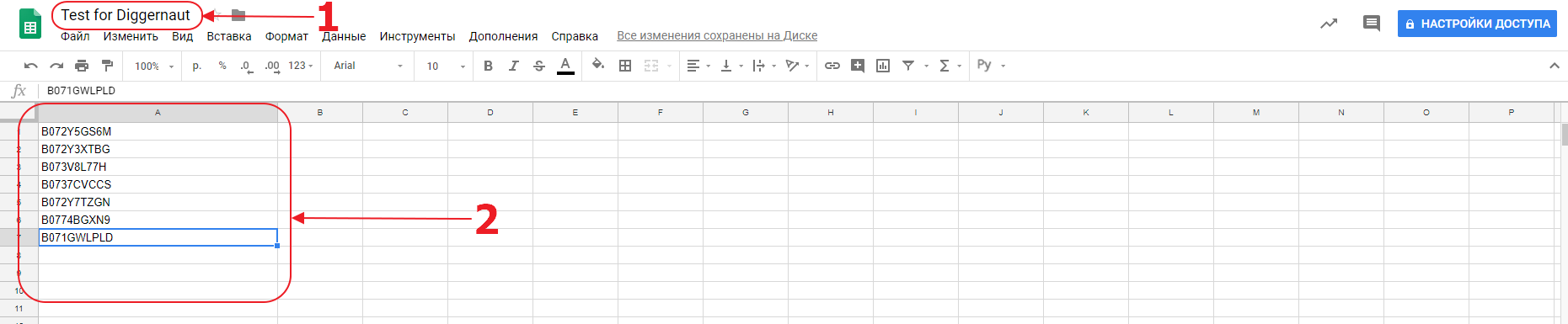
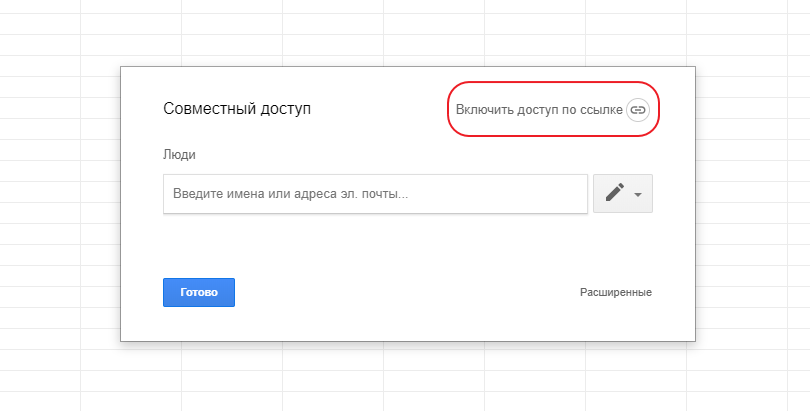
Теперь нам нужно установить доступ к этому документу по ссылке для всех без логина. Для этого нажмем на кнопку:

И за 4 простых шага установим доступ для всех у кого есть ссылка:
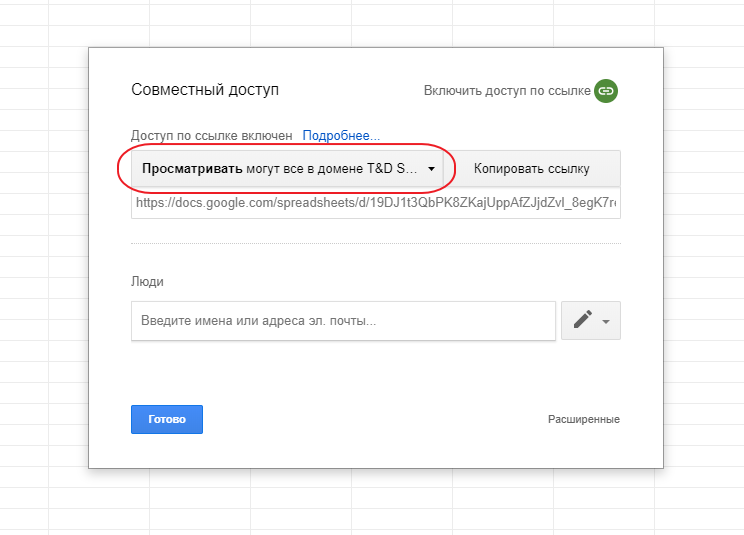
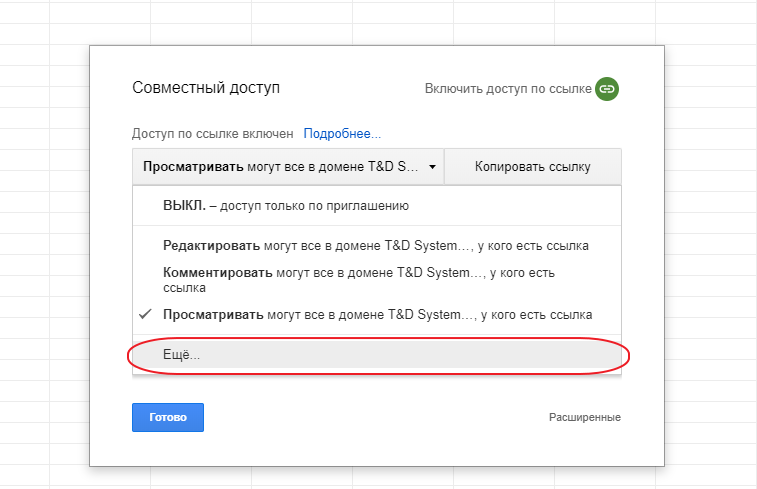
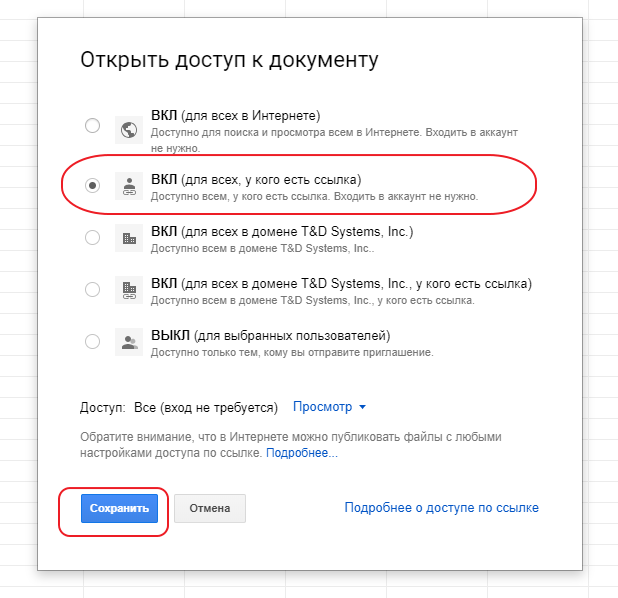
После чего скопируем ссылку в буфер обмена и нажмем кнопку готово:
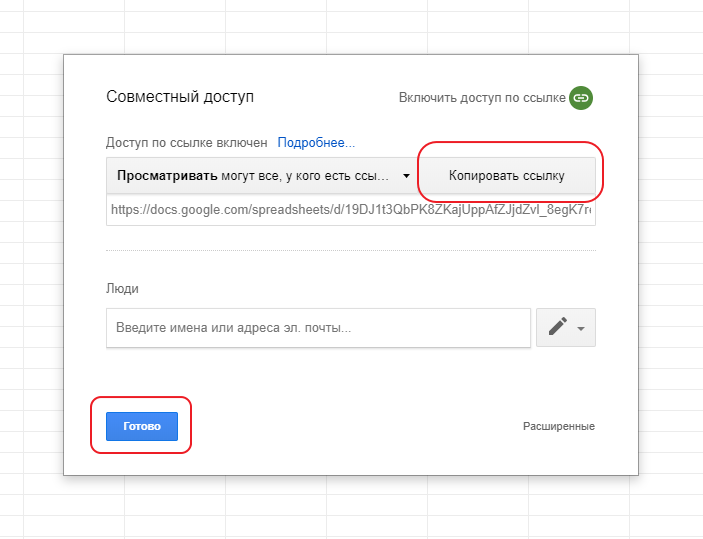
Теперь в нашем буфере обмена есть ссылка на наш Google Spreadsheet документ. Но вы не должны вставлять его в таком виде в ваш парсер, потому что нам нужен XLSX файл. Для этого нам потребуется извлечь из ссылки ID документа. Это делается очень просто. К примеру наша ссылка выглядит следующим образом: https://docs.google.com/spreadsheets/d/19DJ1t3QbPK8ZKajUppAfZJjdZvl_8egK7rec8ctO_fs/edit#gid=0
ID документа это длинный буквенно-цифровой код между двумя слэшами: 19DJ1t3QbPK8ZKajUppAfZJjdZvl_8egK7rec8ctO_fs.
Ссылка на скачивание XSLX формируется сделующим образом: https://docs.google.com/spreadsheets/d/{%ID%}/export?format=xlsx, где вместо {%ID%} нужно поставить наш ID документа. Таким образом ссылка на наш XLSX файл будет такая: https://docs.google.com/spreadsheets/d/19DJ1t3QbPK8ZKajUppAfZJjdZvl_8egK7rec8ctO_fs/export?format=xlsx
Именно эту ссылку мы и будем использовать в нашем парсере. Давайте посмотрим в какую структуру превратится наш XSLX файл когда его прочитает парсер:
---
config:
agent: Firefox
debug: 2
do:
- walk:
to: https://docs.google.com/spreadsheets/d/19DJ1t3QbPK8ZKajUppAfZJjdZvl_8egK7rec8ctO_fs/export?format=xlsx
do:Запустим наш парсер в режиме отладки и посмотрим в его лог. Мы увидим, что Diggernaut трансформирует XLSX файл в такую структуру:
<html><head></head><body><doc>
<sheet name="Лист1">
<row class="1">
<column class="1">B072Y5GS6M</column>
</row>
<row class="2">
<column class="1">B072Y3XTBG</column>
</row>
<row class="3">
<column class="1">B073V8L77H</column>
</row>
<row class="4">
<column class="1">B0737CVCCS</column>
</row>
<row class="5">
<column class="1">B072Y7TZGN</column>
</row>
<row class="6">
<column class="1">B0774BGXN9</column>
</row>
<row class="7">
<column class="1">B071GWLPLD</column>
</row>
</sheet>
</doc></body></html>
То есть нам нужно пройти в каждый row > column, прочитать ASIN и забрать с Amazon страницу для каждого ASIN. Распарсить ее и сохранить данные. В результате ваш парсер мог бы выглядеть вот так:
---
config:
agent: Firefox
debug: 2
do:
- walk:
to: https://docs.google.com/spreadsheets/d/19DJ1t3QbPK8ZKajUppAfZJjdZvl_8egK7rec8ctO_fs/export?format=xlsx
do:
- find:
path: row > column
do:
- parse
- walk:
to: https://www.amazon.com/dp/<%register%>
headers:
referer: ''
do:
# ЛОГИКА ВАШЕГО ПАРСЕРА AMAZON ДОЛЖНА НАХОДИТЬСЯ ЗДЕСЬНадеемся, что эта статья поможет вам экономить еще больше времени при работе с Diggernaut.